이번 포스팅에서는 제일 간단한 Web Application 구조에서부터 시작해서
하나씩 덧붙여나가 많은 트래픽에도 감당가능하며 확장하기 쉬운 구조까지 살펴보겠습니다.
간단한 CRUD 기능을 수행하는 Application 구조는 아마 다음과 같을 것입니다.

제일 기본적인 구조입니다. 여기서 성능 향상을 위해서 Cache 기능을 추가할 수 있습니다.
예를 들어 티스토리 블로그를 이용자들 중에서는 티스토리 블로그를 직접 작성하는 사람들보다는 단순히 다른 사람이 쓴 블로그를 읽는 사람들이 훨씬 더 많을 것입니다.
즉, Write 보단 Read 기능이 더 자주 쓰입니다.
현재 DB에 총 3개의 블로그 글이 저장되어있다고 가정해봅시다. 그럼 누군가가 새로 글을 쓰기 전까지는 티스토리 블로그를 구경하는 사람들은 모두 똑같은 3개의 글을 보게 될 것입니다.
그런데 이렇게 블로그 글이 업데이트가 되지도 않았는데 매 요청마다 DB로부터 저장된 글들을 요청하는 것은 매우 비효율적입니다.
이러한 비효율성을 낮추기 위해서 아래와 같은 구조를 만들 수 있습니다.
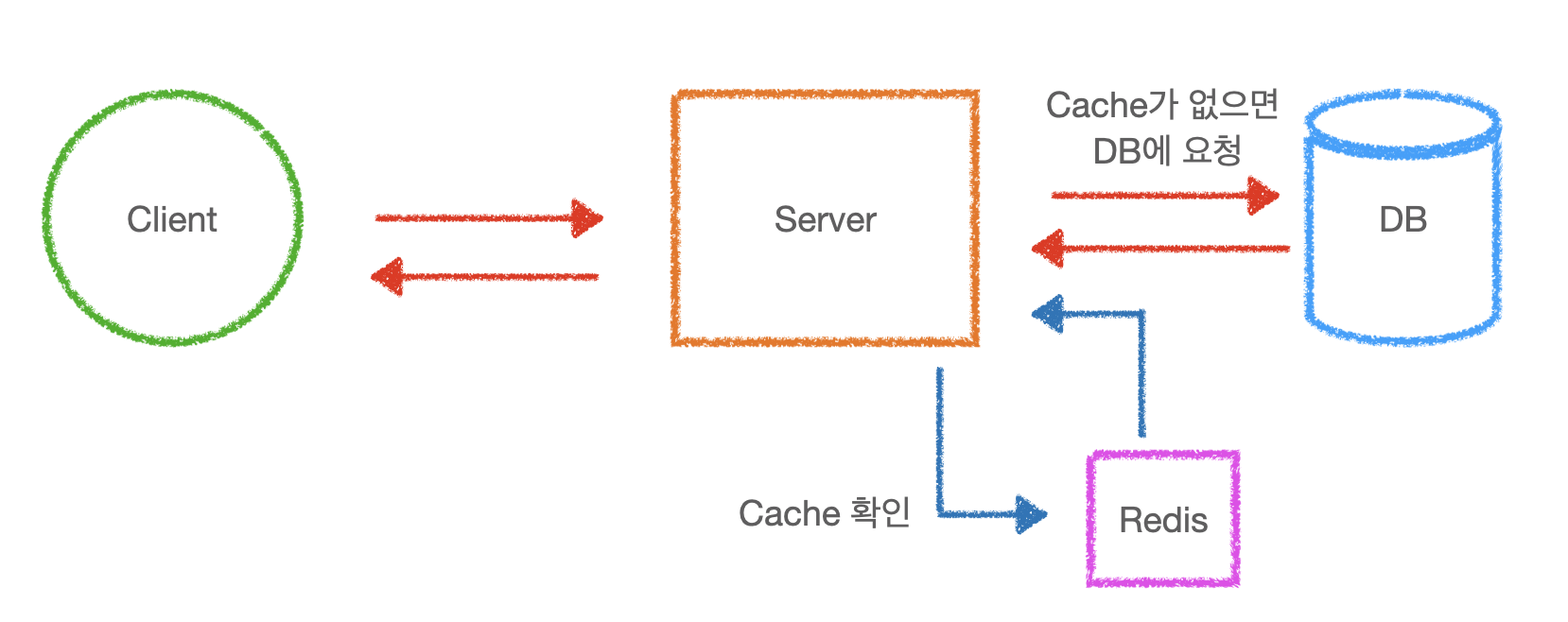
Cache 기능이 추가된 구조입니다.
대표적인 Cache 기능을 하는 DB로는 Redis가 있습니다. (꼭, Redis를 사용해야하는 것은 아니지만 대중적이므로 여기서는 Redis로 설명을 하겠습니다.)
Redis는 In-Memory Database로 말 그대로 메모리 DB입니다. Cache 기능이 없는 제일 기본적인 구조에서 블로그 글이 업데이트가 되지 않았는데 매 요청마다 DB에 요청을 하는 것은 비효율적이라고 했습니다. 왜 비효율적이란 걸까요?
왜냐하면 DB와의 통신은 컴퓨터 기준으로 상당히 많은 시간이 걸립니다. CPU와 메모리의 통신속도와 비교했을 때 하드디스크와의 통신속도는 훨씬 더 뒤떨어지기 때문에 Redis 같은 In-Memory DB를 사용하게 되면 속도 향상을 높일 수 있습니다.
그런데 이런 의문을 던질 수도 있습니다. 만약 Cache hit를 하지못하면 DB통신시간+Redis에 확인하는 시간이 소요되므로
더 비효율적일 수 있다는 의문입니다.
맞는 말일 수도 있겠지만 Cache hit의 비율이 정말 낮지 않는 이상은 위에서 말했듯 Memory와의 통신속도가 훨씬 빠르므로 성능 향상을 기대할 수 있습니다.
현재 구조에서는 Cache 기능의 추가로 성능 향상은 기대되나 단일 서버이기 때문에 엄청난 트래픽이 몰릴 경우 처리량의 한계가 있고 서버가 다운될 수도 있습니다. 이를 위해 아래와 같은 구조를 만들어 볼 수 있습니다.

서버를 늘려서 병렬적으로 처리하는 것입니다. 요즘에는 대부분 Docker를 이용해서 컨테이너화를 하여 관리합니다.
동일한 서버코드를 동일한 환경에서 편리하게 작동시키기 때문입니다.
이렇게 한 대의 서버에서 여러 대의 서버로 늘렸다면, Load Balancer의 역할을 하는 서버 역시 필요합니다.
Load Balancer란 사용자들의 요청을 처리할 수 있는 여러 서버에게 분배하는 역할을 합니다. 요즘에는 nginx가 많이 사용됩니다.
이제 많은 트래픽도 문제 없이 처리할 수 있는 것처럼 보입니다. 그러나 한가지 문제점이 남아있습니다.
현재 구조를 보면 DB는 1개만 존재합니다.
즉, 앞단에서는 많은 트래픽을 처리할 수 있지만 DB는 1개이기 때문에 뒷단에서는 병목현상이 발생할 수 있습니다.
이를 위해 아래와 같은 구조를 만들어볼 수 있습니다.

메시지 큐가 추가된 구조입니다. 메시지 큐에도 여러 종류가 있지만 많이 사용되는 메시지 큐 중 하나인 RabbitMQ를 기준으로 설명해보겠습니다.
Producer란 이름처럼 큐에 공급을 하는 역할을 합니다.
서버로부터 온 요청을 Exchange에게 넘겨줍니다. 그럼 Exchange는 요청의 목적에 맞게 각 큐에 분산 시켜줍니다.
예를 들어 두 개의 큐가 있고 하나는 블로그 글을 읽는 요청, 나머지 하나는 블로그 글을 쓰는 요청에 관해 처리한다면
각 요청들을 적절한 큐에 보내주는 역할을 합니다.
이렇게 함으로써 서버 입장에서는 비동기 처리가 가능해집니다. MQ가 없던 구조에서는 DB로부터 응답을 받아야 다음 작업을 할 수 있었는데 이제는 Producer에게 넘겨주기만 하고 다음 작업을 하기 때문입니다.
Consumer는 큐에 쌓인 요청들을 가져와서 처리를 하는 역할을 합니다.
기존 구조에서는 서버와 DB가 강하게 결합되어 있었지만(DB의 요청을 받아야 다음 작업을 하므로)
이렇게 MQ를 사용함으로써 느슨한 결합을 만들 수 있었고 MQ가 완충제 역할도 해주게 됩니다.
여기까지 Scalable한 Web Application을 만들기 위한 구조였습니다.